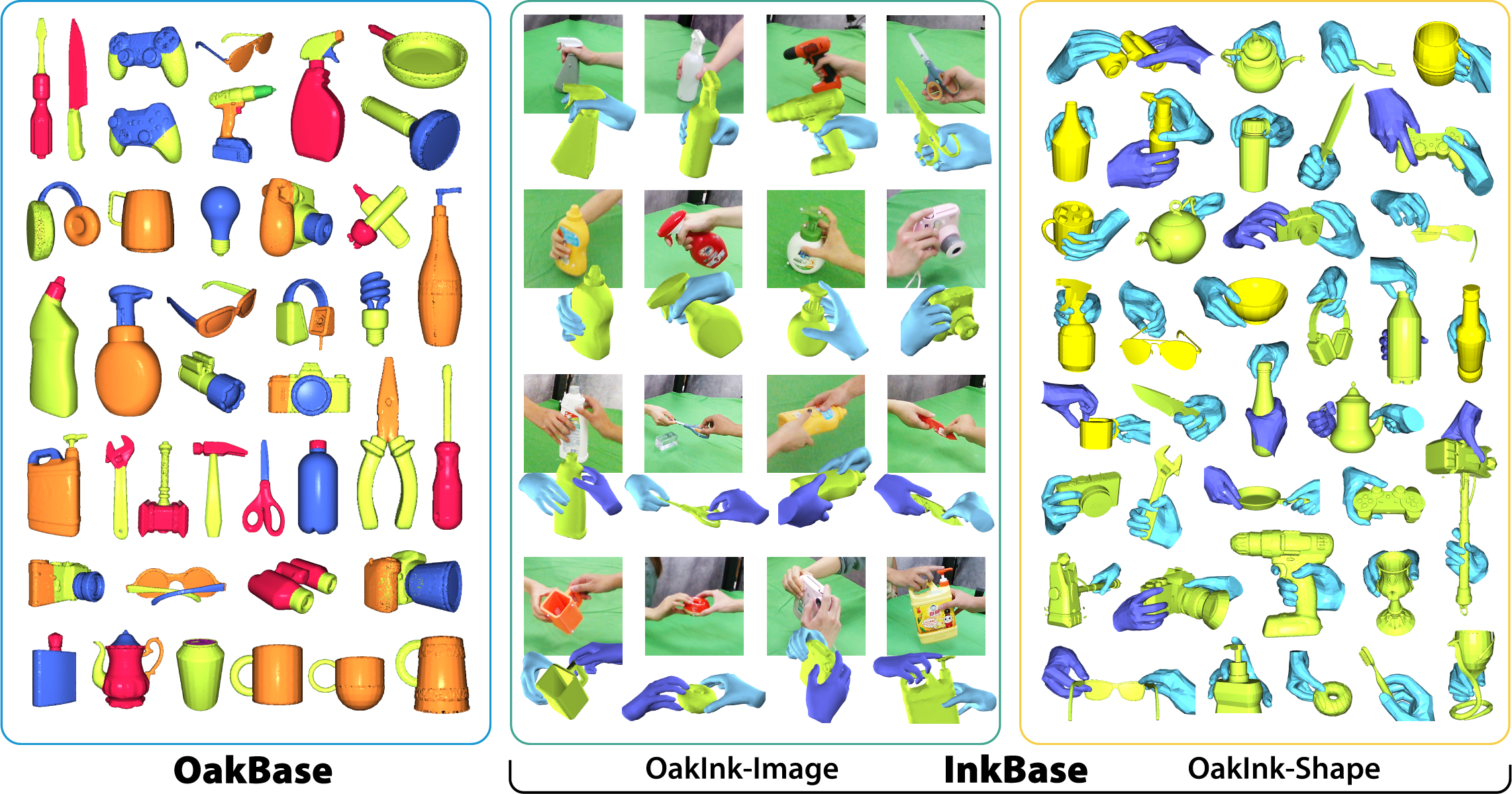
$OAKINK_DIR/zipped as follow
$OAKINK_DIR/zipped
├── OakBase.zip
├── image
│ ├── anno_v2.1.zip # access via Google Forms
│ ├── obj.zip
│ └── stream_zipped
│ ├── oakink_image_v2.z01
│ ├── ...
│ ├── oakink_image_v2.z10
│ └── oakink_image_v2.zip
└── shape
├── metaV2.zip
├── OakInkObjectsV2.zip
├── oakink_shape_v2.zip
└── OakInkVirtualObjectsV2.zip@InProceedings{YangCVPR2022OakInk,
author = {Yang, Lixin and Li, Kailin and Zhan, Xinyu and Wu, Fei and Xu, Anran and Liu, Liu and Lu, Cewu},
title = {{OakInk}: A Large-Scale Knowledge Repository for Understanding Hand-Object Interaction},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}